
The Relational Database is dead.
It had a long, distinguished life that started in 1970 with Dr. Edgar F. Codd, but it has since seen its day. Like the sextant, slide rule, and punch card, relational databases are becoming relics of the past as the industry moves towards better, faster, and awesomer.
Setting aside the fact that relational databases are incredibly, mind numbingly slow, they have a much more fundamental problem: they do not model reality. Take a look at the world around you. Go ahead, shift your eyes from the screen and survey your surroundings.
Did you see a perfectly rectangular world made up of rows and columns? What about schemas? And tables (i.e. the kind without four legs)? Of course not! The world isn’t made-up of that stuff, nor is it very easy to model reality with such things.
Depending on what you’re looking at, the room you’re in has dimensions, contains walls and maybe window coverings. The furniture in a room is constructed from blueprints/plans using wood and metal, which in turn are cut to size and are made up of even smaller things like molecules. And those of course break down to atoms, which have sub-atomic particles, and quarks. The point to take home is that nowhere in this picture is row or a column; the world just simply doesn’t work like that.
Another inherent problem that relational databases have is that, fundamentally, they’re designed for insecure developers. This whole notion of “data integrity” is a crutch for the weak that cripples the able-bodied. I don’t need some database telling me what data I can and can’t store: accept the bytes that I give you, and give them back to me when I ask. I know what they are, I know what they’re supposed to be, and I know how to use them, thank you very much.
Databases, Rethought
The latest breed of database – post-relational, NoSQL, whatever you want to call them – are certainly promising. They have exciting names like CouchDB and MongoDB, and they work incredibly fast. Plus, they’re built to work hand-in-hand with the single-most fundamentally game-changing technology ever: JavaScript.
Think about and savor that last point for a moment. Mmmm, JavaScript. Think about how much code you’d not have to write if you could go directly to your database from Client Script.
The other wonderful thing about the next generation of databases is that they’re infinitely extensible. In the relational world, it’s just about impossible to change the schema once deployed, so many forward-thinking developers create Entity-Attribute-Value tables to accommodate change.
Non-relational databases, on the other hand, are built around this very principle! Want to add an attribute to something? Just do it in your code! The database will figure it out.
Looking Even Further
As great as the new breed of database are, they too are fundamentally flawed. Sure, they’re fast, but more like speed-of-sound instead of speed-of-light. If Moore’s Law taught us anything, it’s that fast ain’t fast enough.
Sure, these new databases can more-than power today’s applications, but what about the next generation? I’m talking paradigm-shifting applications that are so amazingly innovative that our primitive Web 2.0 brains can’t even imagine them today. It’d be as futile as trying to explain Twitter to someone from 1999.
To prepare for the future, we need something drastically different. Something that, like many innovations past, amalgamates the trends, calls them something similar, and then adds a version number to imply that what came before it was old. This, my friends, is Datastores 2.0.
Introducing APDB – the World’s Fastest Database
I’m proud to announce that APDB – named after yours truly – is finally ready for public release. I could write an entire book on the database engine (and in fact, I am), but I’ll boil it down to the flagship feature.
APDB utilizes the physical memory locator (CHS# - Cylinder, Head, Sector) as data-access keys.
Think about that for a moment. Relational and post-relational databases have the notion of index look-up, which means that retrieving a piece of data involves a long, arduous process:
- Find, on disk, where the appropriate index file is stored
- Look for a free block of RAM in which the index file can be loaded
- Load the index file into memory
- Iterate over each index entry until the desired key matches the index key
- When/if found, load the actual data location into memory
- Find, on disk, where the actual data is stored using the index locator
- Look for a free block of RAM in which the actual data can be loaded
- Load the actual data into memory
With APDB, this process is reduced to one step: go to the actual location that matches the index key specified. No middleman, index files, or other nonsense needed; just go directly to the data you want.
While some see disadvantages with physical locators, APDB utilizes these as advantages. Take updating, for example; by default, APDB allocates a small amount of data at the end of each object (remember: space is cheap). In the event that more data needs to be added to the object later, the sectors can be “chained” with ease.
The API for APDB, accessible via JavaScript, COM+, TCP, shared memory, and plenty of other channels, is as simple as can be. For example:
- int Persist(int disk, int head, int cylinder, object data) – persists any object (string, int, date, customer record, jpeg, etc) to the specified location and returns the sector number allocated
- void Chain(int disk, int head, int cylinder, int sector, object additionalData) – persists additional data to the specified location, automatically chaining sectors as needed
- object Retreive(int disk, int head, int cylinder, int sector) – retrieves an object from the specified location
As you’ll notice, not only can APDB store any type or size of data, but it can do so in an unlimited way, offering infinitely infinite extensibility.
It can index it however you’d want to. Why? Because you’re in control of making your own indexes. With everything based on physical locators, indexing is braindead easy. Just write a few helper methods (or use APDB Recipes) to persist to your index blocks, and you’re good to go. A pattern that I’d recommend is to simply use the first head on each disk for your index storage. It’s more than you’ll ever need.
The APDB Engine & Architecture
When I set out to develop APDB, I knew it’d be a challenge. Performance is paramount, and there’s only one language up for the job. It’s certainly not C, as everyone knows it’s not exactly clever when it comes to overloading registers to save space. Assembly was an option, but going directly with machine code allowed for a bit more tighter control with regards to how memory was utilized within the program code of APDB.
Of course, the real challenge with getting APDB running was wrangling control of the hard drive itself. You see, ever since the introduction of the Logical Block Addressing standard, we software developers have had no control over where something gets stored on a disk. That’s all virtualized and determined by the little microprocessors on the hard drive itself.
Fortunately though, despite the multitude of hard drive brands, there are really only two suppliers who produce microcontrollers, and both of them use firmware. And not just firmware, but easy-to-disassemble firmware. It took me all of eight minutes to figure out how to expose the drive controller’s physical addressing subroutines by remapping them through the now-obsolete writepath coupling mechanism.
By rewriting the harddrive’s firmware, APDB can operate in the most performant mode possible.
Installing APDB
APDB is a stand-alone application / Windows Service, and requires very little to run. Although the APDB Engine is written in machine code, I used .NET 2.0 for menu stuff, so you’ll need to have that installed as well.
All you need is a dedicated, IDE hard disk (3.5” only, for now), preferably one of the following models:
- Seagate/Maxtor –models number starting with ST3 or STM3 and ending with A, ACE, AV, or RK
- Toshiba – all drives bigger than 140GB
- Western Digital –models number start with WDA, WDE and end with A,B,C, or E
- Hitachi/IBM – all Deskstar drives up to 1.27TB
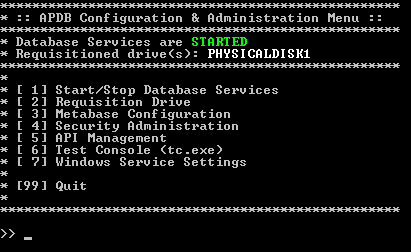
After requisitioning your secondary hard drive for use by APDB, the service will be started, and requests to the APDB engine will be fulfilled.
Read to try it? Give it a shot. The current version is 1.3.9, and is a stable production release. There are no known bugs.