
I was having lunch with a colleague the other day when his phone rang with the distinctive office ringtone. Rolling his eyes, he excused himself to take the call. It was just a run-of-the mill workplace emergency, but there was one thing he said that I couldn’t help overhearing: “fine! I guess we’ll just do a new release for QA.”
It stood out like nails on a chalkboard. “Huh, what do you mean?” he responded when I asked him about it, “they were trying to fix the build, but I dunno, they couldn’t, so I said to do a new release.”
My palm immediately met my forehead. Don’t get me wrong, this guy is an incredibly talented lead developer, but his team’s mangled processes caused more calamities than a cadre of cheap, kerbleckistanian coders. It was no wonder the testing and QA cycle was always fraught with failure.
That got me thinking. Developers – whether rock-star or rock-bottom – don’t really know the process, either. It’s as if we’re all accountants who think that debits and credits refer to the money withdrawn from or deposited to a bank account. It’s actually a lot more complicated than that, as are the concepts of releases and builds.
In fact, it took me quite a few years as a developer – and a bit of time working on BuildMaster – to realize that not only is this a process, but a whole discipline. This discipline – which, for lack of a better term, I’ll call Release Management – sits outside the realms of computer science (“solving problems with software”) and software engineering (“sanely structuring software”), but is equally important in creating and maintaining quality software.
It doesn’t matter how great the code is (nor how well it’s documented or tested) when there are production problems amidst a dozen different-but-related applications that are maintained by various teams and released on various schedules. While these problems are eventually solved after a blame game between developers, project managers, analysts, and even the poor fellow who moved the files, the real culprit is the process. Or more specifically, the lack thereof.
The Process of Releases and Builds
The nouns “release” and “build” are words we’ve obviously all heard before, and most certainly even used. But like debits and credits in accounting, they’re often misunderstood to kinda/sorta mean their commonplace definitions. In my colleague’s case, releases and builds were basically the same thing, except a build turned into a release after it was sent to QA, and only patches were allowed to be made to releases.
Following are the actual definitions for this context.
- Release - represents a planned set of changes to an application. The release could be planned far in advance and require tens of thousands of developer hours to implement, or it could be a single line change rushed to production in an emergency.
- Build - represents an attempt at implementing the requirements of a particular release. It also serves as a snapshot of an application’s codebase that is tested throughout the application’s environments before going into being “released” (i.e. deployed to production, shipped to the customer, etc.)
When they’re used incorrectly and/or interchangeably, the important conceptual differences become blurred, and unnecessary challenges start to rear their ugly head. Though seemingly subtle, it’s an important distinction, not unlike like that of classes and interfaces, and virtual and abstract methods.
Here’s a quick diagram to illustrate not only the differences, but the process.
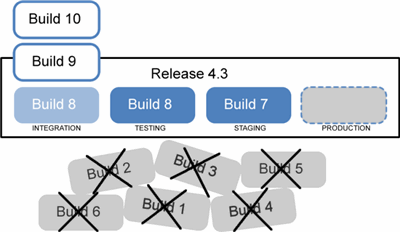
It’s a universal process, and regardless of the size or scope of a release, they’ll all run through the same steps.
- Someone (business analysts, developer, product manager, etc) decides that certain changes are needed to an application,
- and they generally document these changes in some sort of issue tracking system, or they’ll use another tool or process (perhaps even shouting over the cubicle wall).
- These changes constitute a Release.
- A developer sees the changes needed, and modifies the application’s source code to implement the requirements.
- Once ready, the code is compiled, built or otherwise assembled into a Build.
- This Build is then deployed into a non-production application environment such as "Integration" or "Staging"
- The Build is tested in that environment.
- The testing could be simply a "smoke test" (i.e., see if the main page loads),
- or it could be in-depth test scripts executed by a tester.
- Hopefully, it’s not a “test of faith”.
- After testing,
- if the Build meets the necessary testing criteria, it is deployed to another non-production environment.
- If the Build is inadequate (due to bugs or the fact that it was a prototype build), it is then rejected and the aforementioned build, deploy, and test steps are run again
- Once a build has been verified as ready, it is deployed (“released”) to production.
With the rules of this process defined, we can derive quite few patterns and anti-patterns.
Don’t Break The Build
We’ve all heard stories around broken builds, or more specifically, the consequences surrounding one: dunce cap, buying beer, and even scathing insults. But as discussed earlier, there’s a “build” (binary output of a compilation process), and a “build” (snapshot of an application that attempts to implement changes for a release) – “breaking the build” refers to the former, more commonplace definition.
While somewhat related (a build is often comprised of compiled binaries), they’re as different as orange (the color) and orange (the flavor). For example, a build of a PHP application could contain a directory of source files (it’s an interpreted language), a database upgrade script, and the results of a PHPUnit test run.
As such, a build (in the context of releases and builds) can’t really be “broken” if it can’t be built in the first place. And if a build is determined to be broken (i.e. defective), it cannot be fixed – a new build must be created.
Build Immutability and Completeness
To expand a bit further on that last point, one of the most important considerations with a build is that it must be immutable. Whatever is deployed to the first environment (“development”) should be exactly what’s deployed to the final environment (“production”). If it’s absolutely necessary to recompile code after the first environment (perhaps to remove DEBUG symbols), then the codefiles used to recompile should be identical and put through equally rigorous testing. Of course, this does not preclude the use of environment-specific configuration files or other data-driven components, but managing those is a whole a separate soapbox.
It’s also important that a Build is deployed in its entirety, and not piecemeal. That’s not to say that a directory synchronizing tool should be avoided, but more that every change represented in a build must be deployed. If, for example, a build contains four files that changed, then all four files must be deployed. If one of the changes isn’t “ready” to be deployed, then it never should have been included in the build.
There Can Be Only One
While a whole lot of builds may be created for a given release, only one build will ever be released. This is especially obvious in the case of shipped software (customers aren’t given two different builds to pick from), but for in-house applications it’s not as clear.
Once a build has been deployed to production, the application has changed and will require a new release to be changed again, even if it’s a simple, one-line fix. This “patch” release can follow a different testing workflow (straight from source control to production), is still a new release.
Build vs. Version
The concept of a “version” is to uniquely identify an application at a particular point in time, and no two versions can be the same. With releases and builds, the version number simply becomes a concatenation of the release and build numbers. For example, Build 4 of Release 2.3 is version 2.3.4.
Of course, since there can only be one (final) build per release, it’s entirely acceptable to use only the release number after shipping (e.g. for marketing purposes). Version 2.3 refers to the released build of Release 2.3.
Release Planning and Changes
Just as you can makes changes to code without using an issue tracking system (though this is unadvisable even in the most agile of environments), applications can be released without a formal process. But this is just as unadvisable, as it leads to an unnecessary chaos.
Since a release will occur regardless, you may as well do some sort of release planning. It could be as simple as using a whiteboard to write down some release numbers and each release’s target date. Or you could use a spreadsheet. Or a wiki. Or a platform like BuildMaster. It really doesn't take much.
Once releases are formally defined, you can easily associate changes with a given release. Nearly all issue tracking systems will have a field for this, whether they’ve called it version, iteration, target, or release. Those that lack a field generally allow you to define your own fields.
Although it’s likely that most changes will simply go in the “active” release (i.e. the next one to be deployed), following this rule allows better planning and organization, even if the changes will be shifted or moved into further out releases. It’s a much better system than trying to overload a “status” field with values like “this version” and “next version.”
Introducing the Jenga Pattern
When changes are associated with builds (thereby making them mutable), or when they’re deployed piecemeal, the “Jenga Pattern” will start to emerge. Named after the popular game where players rearrange wooden blocks on a tower and avoid collapsing it, the Jenga Pattern introduces untested application changes that can lead to application failure.
When a build is a complete, immutable, and fully deployed, it can be thought of as a nicely stacked, undisturbed Jenga tower, with each block in the tower representing a code file, a library file, or module. While this tower may be unsuitable in and of itself, the simple act of moving it through different testing environments will not cause it to collapse.
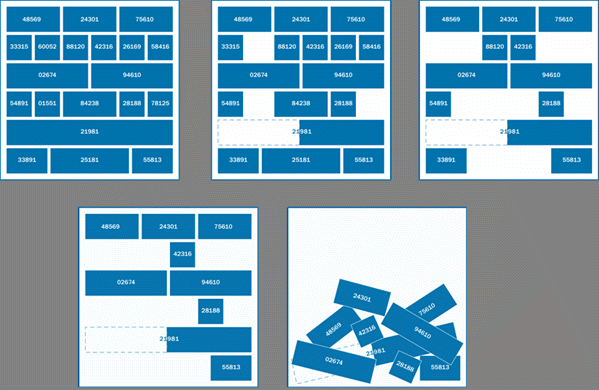
However, if the blocks are rearranged between different environments, it will nearly be impossible to know if a defect is a result of the code or deployment of the code. As more blocks are rearranged between environments, the risk of collapse will increase. While you can try to judge whether a block rearrangement will trigger a collapse, no one can do so with perfect accuracy.
Consider this overly-simplified example.
// MathLibrary.lib
class Math {
const PI = 3.14159265; //fixed (used to be 3.0)
function add(a, b) { return a - b; }
}
// Application.lib
class FunFact {
function print() {
writeline("Pi is " + Math.PI);
}
}
If a build contains these two library files, a simple test would reveal that MathLibrary.lib is defective because the add() method is broken. However, Application.lib will test just fine, as it relies on the recently-changed PI constant, which works just fine. However, deploying only Application.lib would introduce a new problem: FunFact.print() will no longer function as it did during earlier testing, since the code for PI had not been deployed. Obviously, this would be easily spotted in this example, but imagine “crunch time” in a real application: it’s not so easy to spot subtle deployment problems, especially when the application consists of a front end website, middle-tier webservices, and a database backend.
Promotions
Up to this point, I’ve avoiding using the word “promotion” altogether. But it’s a vital part of the release management process – perhaps equally as much as releases and builds.
Whereas a release identifies changes to an application and a build implements those changes, a promotion delivers the changes. More specifically, a promotion is an indication that a given build has been approved for deployment to a certain environment. This approval can require form 27B-6 to be filled out in triplicate, or it can axiomatically occur as a result of someone deciding to just go and deploy a build.
Just as a release may have many builds, a build may have several promotions. As the commonplace definition implies, promotions occur in a linear direction towards production (e.g. “integration”, “testing”, “staging”, “production”), and an environment-specific promotion can occur once per build.
It also stands to reason that a build cannot be “demoted”. If a build is determined to be inadequate for a particular stage/environment, then it will always be inadequate as builds cannot change. An inadequate build must be rejected.
While they cannot be demoted, builds are generally superseded as the result of another build’s promotion. For example, if two builds cannot share an environment (as is often the case), when Build 12 is promoted to the staging environment, Build 11 is axiomatically rejected.
It’s important that promotions are treated as a distinct concept, and not as an attribute of a build. For example, if you had a screen that represented a build, having a dropdown list called “environment” with the values “integration”, “testing”, “staging”, and “production”, is not nearly sufficient, as it does not convey when the build passed through each environment, and who was responsible for doing that.
Tying it All Together
After I explained the concepts of releases, builds, and promotions to my colleague, I could tell that something clicked. And not just because I’m a keen observer of subtle facial patterns – he actually said, “wow, that makes all kind of sense.” I had a similar reaction myself after many years of doing release management the wrong way.
I suspect there are a lot of reasons why release management is such an underdeveloped discipline – the relatively new nature of non-mainframe development for business systems, the “recent” introduction of agile practices, and the drastically decreasing cost of hardware (thereby allowing multiple testing instances for applications) – but it’s a discipline that needs more attention, especially as we move towards greater complexity and more frequent changes.
For example, something as daunting as cross-application dependencies (e.g. the MobileApprove application requires the WHS Web Services application), can be solved with a simple application of this process. When a build of a dependent application is created, simply noteing which builds of which applications it depends upon. When it comes time for deployment, it’s simply a matter of verifying that the depended-upon build has already been promoted to target environment.
Fully deploying your complete and immutable build will significantly reduce the risk of deployment-related “bugs”. And, by defining changes at the release level and using promotions, it’s no longer a question of what’s deployed where and when.
Of course, as important as it is to define the process, the process must also be followed. It doesn’t take much, and unlike other disciplines (source control, for example), you can start with nothing more than a whiteboard. Eventually, more groups– project managers, developers, analysts, network operations, executives, etc – will start to catch on and even use the terms to communicate with each other. A little bit of process will go a long way to help solve a multitude of problems and, at the end of the day, let you get back to development (or whatever it is you do).
Additional Tools - there are plenty of ways to facilitate this process, including whiteboards and a simple spreadsheet. <shameless_plug>BuildMaster, a product I’ve been working on at the day job, was also designed from the ground-up to automate and facilitate this entire process.</shameless_plug>