
Your introduction to source control probably was a lot like mine: “here’s how you open SourceSafe, here’s your login, and here’s how you get your files... now get to work.”
For the most part, that works just fine. We’re already familiar with the nature of files and directories, so introducing the concepts of checking-in and checking-out aren’t a huge leap. Repositories, merging, and committing become second-nature just as easily.
But there’s a whole lot more to source control than just that. And, as someone in a fairly unique position of working with virtually every source control system out there (a hazard of the day job: BuildMaster needs to integrate with them all), I’ve learned that there are far more similarities than differences.
This especially holds true with the latest breed of distributed version control systems. Sure, certain operations may be easier to do – but if they’re the wrong thing to do, then it’s that much easier to make mistakes.
Back to Basics
If we’re going to take a good, hard look at source control, let’s do something we should have all done a long time ago, before even touching a source control client. Let’s go back to the basics. The very basics.

It all starts with bits: an unfathomably large and virtually endless stream of 1’s and 0’s. Whether it’s the 16,000,000 on a 3.5”floppy disk or the 4,000,000,000,000 on a desktop hard drive, bits represent a line – the first dimension – and, in and of themselves, bits are entirely meaningless.
That’s where the second dimension – the file system – comes in.
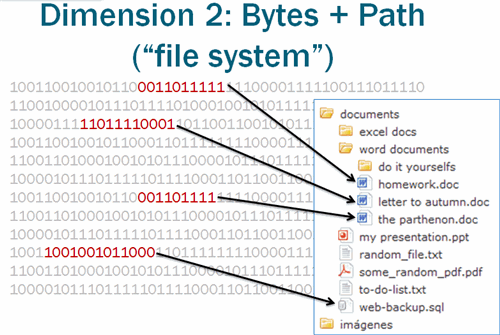
The file system intersects this near-infinite line of bits and creates a path. Bits 5,883,736 through 6,269,928 now have meaning: they represent C:\Pictures\Kitty.jpg and the adjacent 4,096 bits may contain metadata understood by the file system, such as “date created” and “last modified by user”.
The second dimension is the world that every computer user lives in, but we know of a third dimension: the delta.

A delta not only represents the bits that were changed in the first dimension, but also the paths that were changed in the second dimension. This third dimension – the repository – provides a perfect history of changes, allowing one to revert to any state at any time. As a whole, a three-dimensional system is known as revision control.
Revision Control -vs- Source Control
There’s one key distinction between revision control and source control: the latter is a specific type of the former. With that, we can arrive at fairly broad yet concise definition.
Source control: change management for source code
Just as a flathead screwdriver can be used a chisel, a source control system can be used to do things that are completely unrelated to source control. Sometimes that’s okay if you only need to chisel off the smallest bit of debris, but it’s far too easy to mistake your favorite source control system as the golden repository.
While the list of what a source control system shouldn’t be used for is near infinite, the top three misuses tend to be:
- Document management (such as SVN For HR, or even developer documentation)
- Storing compiled binaries
- Littered with gigabytes of video and picture files
A little bit of misuse is okay, so long as you remember that source control is for source code. It’s not a document manager, an artifact (build output) library, a backup solution, a configuration management tool, etc.
Source Control Operations
There are dozens of different source control systems on the market, but all must implement at least two core operations.
- Get – retrieve a specific set of changes (files, directories, etc) from the repository
- Commit – add a specific set of changes to the repository
Many source control systems will also implement a locking mechanism that prevents a Commit against a specific set of files. This yields two additional operations:
- Check-out – Locking a specific set of files and then Getting the latest revision of those files
- Check-in – Unlocking a specific set of locked files and then Committing changes against those files
This notion of locking files has created two distinctly different philosophies for maintaining code:
- Check-out + Edit + Check-in – before making any changes to a file, a developer must check-out the file, and while it’s checked-out, no other developers can make changes against it until the file is checked-in
- Edit + Get/Merge + Commit – before committing a change to the repository, a developer must get the latest version of the file and merge any changes made since the last time he retrieved it
The debate over which practice is better is largely religious: for every advantage one technique holds over the other, there’s an equal disadvantage. Some projects are better suited for Edit + Get/Merge + Commit, while some teams are better suited for Check-out + Edit + Check-in. It doesn’t really matter.
Do what works for your team and, if you don’t get to make that decision, then just learn to adapt. There are far more important battles to win, especially when you enter… the fourth dimension.
The Fourth Dimension
Up until this point, the distinction between revision control and source control has been in name only. The concepts of organizing bits into files (second dimension) and maintaining changes in these bits (third dimension) apply to data of all kinds.
But source code – though just a bunch of text files – is a special kind of data: it represents a codebase, or the living blueprint for an application that’s maintained by a team of developers. It’s this key distinction that makes source control a special case of revision control, and why we need an additional dimension for managing changes in source code.

While a three-dimensional system manages a serial set of changes to a set of files, the fourth dimension enables parallel changes. The same codebase can receive multiple changes without having any impact whatsoever on another. It’s not unlike parallel universes: whatever Bizarro Alex does in his universe has no impact on me.
Fork Me
The quickest way to enter the fourth dimension is through an operation called Fork.
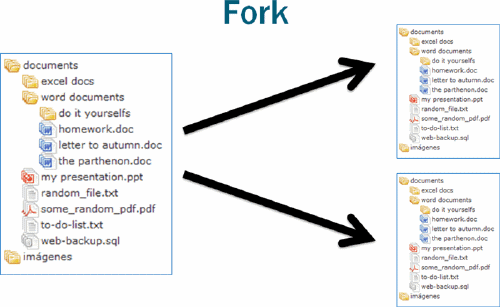
A fork copies a three-dimensional repository, creating two equal but distinct repositories. A commit performed against one repository has no impact on the other, which means the codebases contained within will become more and more different, and eventually evolve into different applications altogether.
While forking is a way of life for open source projects, the operation offers little benefit for a team maintaining a single application. For this type of development, the parallel repositories must come together at some point through merging.
The Urge to Merge
Merging is a concept that’s really easy to make a lot more complicated than it needs to be. When we’re looking at things from a fourth dimensional point of view, there are three lower dimensions to merge:
- Bits – a relatively easy task for text files; lines can be added, changed, or deleted, and a smart diff program will help identify these for human inspection
- Paths – files can be moved, renamed, copied, deleted, etc., ideally with the same smart diff program and same human inspection
- Deltas – these are the least important to merge (and some source control systems won’t even bother), and since they’re a mere history of changes, they can get automatically shuffled together like a deck of cards
No matter how smart a diff program may be, if there have been changes in both repositories, merging should always be verified by a human. Just because the diff program reported “no conflicts” and was able to add a line here, and delete a file there, that doesn’t mean the resulting codebase will work properly or even compile.
What the Fork?
Of course, knowing how to merge doesn’t exactly help you understand why parallel repositories needing merging in the first place. The most common reason for this is one of the special types of Fork operations called a Branch.
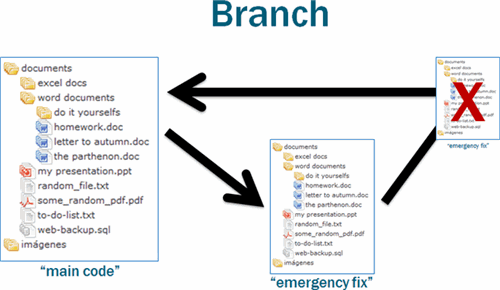
Though its name doesn’t quite imply it, a branch is simply a temporary fork. Changes made to a branch are generally merged back in, but one thing must happen: at some point, the branch has to go away. If it doesn’t, it’s just a fork.
But before we get into the when of branching (it’s a bit… involved), let’s look at another type of fork operation called Label.
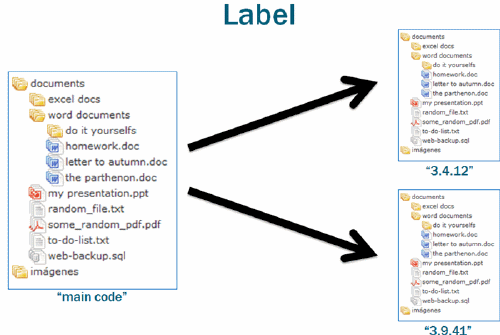
A label is nothing more than a read-only fork. Sometimes (depending on the source control system), they’re called tags, snapshots, checkpoints, etc., but the concept is always the same: it’s a convenient way to label the codebase at a certain point in time. It’s almost like creating a backup or a ZIP file of a directory, except it has a history of all of the changes as well.
The third – and the least used – special type of Fork operation is called Shelf. It’s an unofficial, “working” fork that’s used to manage or share incomplete changes. Changes committed to a shelf may be merged into the main codebase, or vice versa.
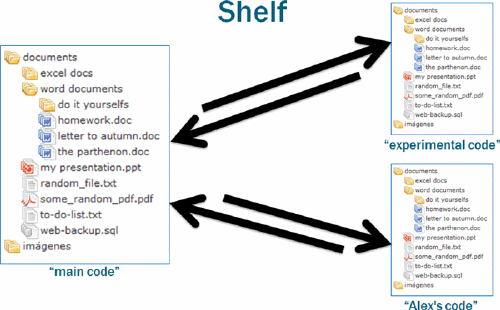
Some organizations may give each developer his own shelf so that he can easily share/merge changes with other developers. Others teams may set-up shelves as some sort of quality gateway – a development shelf, an integration shelf, etc. – to ensure that only “good” changes find their way in real application’s codebase. There’s only one rule about shelves: they should never be used to create builds that are intended for production deployment.
All told, there are a minimum of four forth-dimensional operations:
- Fork – a parallel repository
- Branch – a temporary fork
- Label – a permanent, read-only fork
- Shelf – a “personal” or “working” fork
The most basic implementation is to simply support a “fork” operation and rely on the end-user to maintain sub-repositories. Subversion (and others) create default sub-repositories called /trunk, /tags, and /branches, but yours could just as easily look like this:
/mainline
/labels
/2.5.8
/2.6.1
/2.6.2
/2.6.3
/2.7.1
/branches
/2.6
/2.7
/shelves
/stages
/development
/integration
/users
/alexp
/paula
/groups
/offshore
/vendor993
Depending on how things work behind the scenes, these forks could eat up a lot of disk space... or they could use an indexing system and require hardly any resources at all. Other source control systems will not only optimize the implementations, but they will hide implementation details and give them special names:
- Accurev branches are called “streams”
- CA Harvest: labels are called snapshots
- Source Safe: labeling is its own operation
- Team Foundation Server: shelving is its own operation
How these concepts are implemented behind the scenes is less important than understanding how to use them.
Source Control and Application Development
If you’ve been following my previous soapbox articles, you may recall the last was entitled Release Management Done Right, and discussed the concepts of build and release management. Understanding the differences between builds and releases are as fundamental to application development as debits and credits are to accounting, so as a quick refresher:
- Release - represents a planned set of changes to an application. The release could be planned far in advance and require tens of thousands of developer hours to implement, or it could be a single line change rushed to production in an emergency.
- Build - represents an attempt at implementing the requirements of a particular release. It also serves as a snapshot of an application’s codebase that is tested throughout the application’s environments before going into being “released” (i.e. deployed to production, shipped to the customer, etc.)
Or, in diagram form:
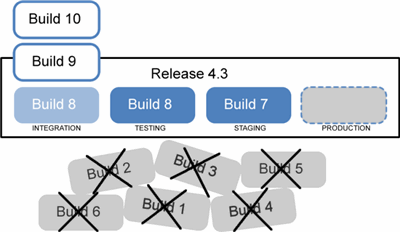
As you’ll recall, a Build is immutable. Remember which special fork is also immutable read-only? That’s right: the label. Whenever you create a Build, you should also create a label. Not only will that help enforce the code immutability, but by knowing which build is in which environment, you’ll also know where your code is as well.
A Tale of Two Branching Strategies
Because a branch is a temporary creation (otherwise, it’d just be a fork), it isolates a particular set of changes to the application’s codebase. That’s basically the definition of a release, which is why the concepts of branching and releases are so intertwined. Branches are a way – actually, the only sane way – to isolate the changes in one release from another.
With the “create branch” button just a click away, there are a plethora of ways to incorrectly branch your codebase. But there are only two correct strategies – branching by rule and branching by exception – and both are related to isolating changes in releases. Because of this, a branch should always be identified by its corresponding release number.
The reason for this is simple: there’s only one trunk (mainline, root, parent, or whatever you want to call it), and the code under that trunk is either what’s in production now (the last deployed release), or what will be in production later (the next planned release). And that means you’re either always branching or only branching sometimes.
Branching by Exception
This is by far the easiest strategy to follow. In fact, if you’ve never branched anything before, then you can still claim that your development team follows this strategy. As the name implies, a branch is only created for “exceptional” releases, and the definition of “exceptional” is defined entirely by the development team.
Exceptional could mean “an emergency, one-line fix that needs to be rushed to production yesterday”, or it could mean “some experimental stuff we’re working on for 3.0.” The main tenet is that you generally use the trunk for developing code and creating builds that will be tested and deployed.
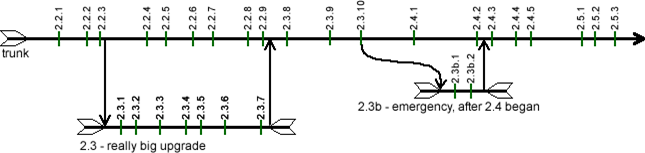
The diagram shows how this strategy works in practice. If we follow the trunk line (which represents a series of changes over time), we’ll see that the story starts with the development being in the midst of Release 2.2. The green, vertical hashes represent labels, and the team appropriately labeled their codebase with a build number (2.2.1, 2.2.2, etc.) whenever they’d create a build.
At some point, they decided to work on Release 2.3 in parallel (it was an exceptionally big release), so they forked their code to a branch called “2.3” and created builds against both releases. Once Release 2.2 was deployed (with Build 2.2.9, we presume), they merged changes from Release 2.3 into the trunk, deleted the branch, and continued creating and testing builds. Eventually, Build 2.3.10 was deemed the winner, so they commenced work on Release 2.4 and even created a preview build (Build 2.4.1) to show off their hard work.
And then, while they were merrily working on Release 2.4, the business delivered some bad news: a serious mistake in production (Build 2.3.10) needed to be fixed yesterday. So, they forked the codebase, but instead using trunk (which had all sorts of new changes for Release 2.4), they forked the label and were able to push the emergency change (Release 2.3b) through to production after two builds. They merged the fix into Release 2.4, deleted the branch, and continued on their way.
Branching by Rule
If every release seems to be exceptional – or if there’s a real need to isolate changes between releases – branching by rule may be worth exploring. In this case, every release gets its own branch, and changes are never committed to the trunk. Since trunk represents the deployed codebase, once a release has been deployed, its changes should immediately be applied (not merged) to trunk, and the branch should be collapsed.
This doesn’t mean you can get away without merging. On the contrary, you need to be extremely careful when working with parallel branches. As soon as a release is deployed, the changes applied to trunk should be merged into all branches.
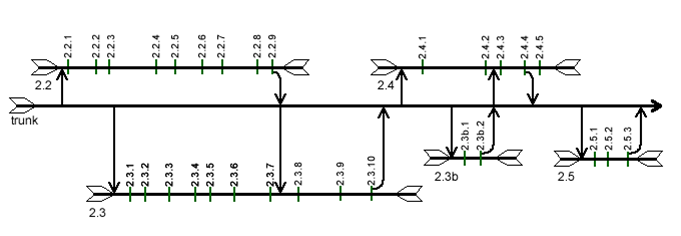
The diagram uses the same conventions as the branch by exception (and thus, I won’t narrate the play-by-play), but there are a few important things to take note.
- Trunk is never labeled; builds are never created from it, and thus there’s no point in labeling
- A branch itself is never automatically merged into trunk; instead, the label that represents the deployed build (e.g. 2.3.10) is automatically merged
- Changes committed after a label (e.g. changes in Build 2.4.5 of Release 2.4) could be lost forever if they’re not merged to another branch
- When changes are automatically merged into trunk (e.g. Build 2.2.9), they’re manually merged (to resolve conflicts, etc) into each open branch (Release 2.3)
Branching by Shelf
One of the reasons that shelves are the least common of the fork operations are that they’re often misunderstood and misused as branches. A source control anti-pattern that some believe is branching looks something like this:
/ /DEV helloworld.c hiworld.c /QA helloworld.c /PROD helloworld.c
There are multiple shelves, each designed to represent a certain stage of testing, and one for production. As features are tested and approved, the changes that represent those features are “promoted” to their appropriate environment through merging. When deploying to an environment, code is retrieved from the corresponding repository, compiled, and then installed.
This source control anti-pattern leads to all sorts of problems, especially the Jenga Pattern discussed in Release Management Done Right. Worse still, these problems grow exponentially and become exponentially difficult to solve as the codebase grow. Though I’ve seen this anti-pattern quite a bit in my career, it seems to be less and less prevalent.
And then came the distributed source control systems.
The Distributed “Revolution”
Traditionally, source control systems have worked on the client/server model: developers perform various source control operations (get, commit, etc.) using a client installed on their local workstation, which then communicates and performs those operations against the server after some sort of security verification.
But distributed source control systems are quite a bit different.
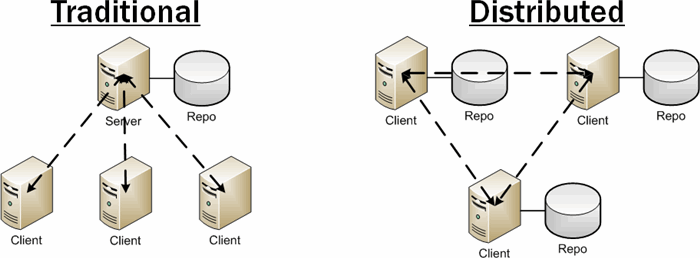
There’s no central server – every developer is the client, the server, and the repository. Source code changes are committed as per normal, but remain isolated unless a developer shares those changes with another repository through “push” and “pull” operations. It’s a paradigm shift, not unlike the BitTorrent shift in the file-sharing world.
But there’s just one problem. Just as BitTorrent needs trackers, applications – especially of the proprietary, in-house variety – can’t be developed peer-to-peer. An application needs to have a central codebase where its code is maintained and from which builds are created. This means that the traditional vs. distributed diagram should look more like this.
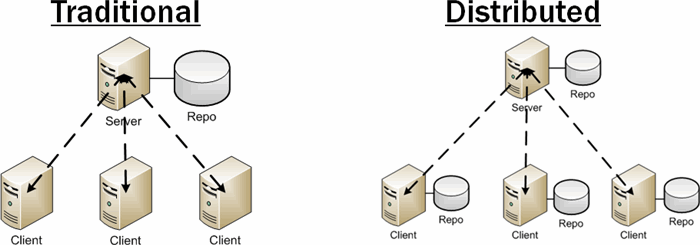
There’s still one big difference: each client has his own fork of the repository. The obvious downside to this is that a repository can grow to be pretty big, and storing/transferring all that history to a local workstation may be time consuming on an initial load. But there’s another subtle disadvantage. In order to add a change to the central repository, developers must perform two operations – a “commit” to his local repository, then a “push” to the central – it may not seem like a big deal, but for certain developers, it’s twice the reason to avoid source control altogether.
That’s not to say that having a local repository is not advantageous, but many of the purported benefits – frequent commits, easy merging, sharing code, patching, etc. – can be achieved with individual shelves. If I wanted to “push” my changes to Paula, I could simply merge changes from my shelf to hers – and vice versa.
Of course, with all the new terminology and the learning curve of the paradigm shift, the notion of branching – or I should say, proper branching strategy – is becoming quickly forgotten. With the ease of forking, the simplicity of merging, and allure of pulling, it only seems logical to branch by shelf and end up picking up Jenga pieces.
This is certainly not to say that distributed version control doesn’t have its place. In fact, the reason it’s become the de facto standard for open source projects is because open source projects are developed vastly differently than proprietary applications. Professional developers don’t submit patches, hoping the business (or another developer) will accept their fix to the bug – they’re simply assigned the task of fixing the bug, and they do it because it’s their job. And they certainly don’t fork applications to start their project.
In The End: Not Really About The Tools
In all of the time I’ve spent working with and integrating different source control systems, I’ve come to one conclusion: it’s not the tool, it’s how you use it. That’s a terribly hackneyed statement, but it seems especially true here. When used to properly manage source code changes – labeling for builds, branching by exception, etc. – even the lamest source control system (*cough*SourceSafe*cough*) will far outperform a Mercurial set-up with a bunch of haphazard commits and pushes.
Understanding how to use source control – not just a specific source control system – will allow you to add some real value to your team. Instead of getting caught up in the great “Check-out/Edit/Check-in” debate or desperately trying to convince everyone to switch to Subversion, strive for a greater goal: use your source control system to properly manage source code changes. That’s why you’re using it in the first place.